
꼭 개발자가 아니더라도, 어떠한 URL의 끝에 붙는 /를 본 적이 있을 겁니다. 이것의 존재에 관해서 궁금해 본 적은 없으셨나요? URL은 정확해야 할 것 같은데 왜 /가 있든 없든 동일하게 동작을 하는 건지에 관해서 말이에요. 결론부터 말하자면, 저것(Trailing Slash)의 존재에 따라서 서버는 다르게 동작합니다. 어떻게 다르게 동작하는 걸까요?
Trailing Slash가 포함되지 않은 경우
서버: 이 Resource는 파일인가보다
- 해당 이름의 파일이 존재하는지 먼저 확인하자.
- 없네? 그러면 이 이름의 디렉토리를 확인해 볼까.
- 있구나. 그럼 해당 디렉토리의 index를 확인하자.
Trailing Slash가 포함된 경우
서버: 이 Resource는 폴더구나
- 해당 이름의 디렉토리가 존재하는지 확인하자.
- 있네? 그럼 해당 디렉토리의 index를 확인하자.
얼핏 봐도 서로 다르게 움직인다는 걸 알 수 있죠? 그런데 우리가 보통 알고 있는 URL이란, Resource에 대한 거라기보다는 도메인에 대한 것일겁니다.
www.google.com?
만약 우리가 구글에서 뭔가를 검색하기 위해 브라우저 주소창에 www.google.com을 입력했다고 생각해봅시다. 그럼 이건 아마 파일이겠죠? 왜냐하면 /가 붙어있지 않으니까요. 그런데 www.google.com이라는 파일? 뭔가 좀 이상하죠? 그렇다고 www.google.com/을 입력해봐도 결과는 같네요? 그럼 이건 디렉토리도 되고 파일도 된다는 걸까요? 그럴 수가 있나요?
사실 이건 Domain URL이라고 불립니다. 위키피디아의 URL스펙을 한번 확인해볼까요?
scheme:[//[user[:password]@host[:port]][/path][?query][#fragment]]이렇게 스펙만 보면 뭐가 뭔지 알기 어려우니까 조금 Human Readable하게 번경해볼게요.
https://www.google.com/someting/noting/anything
즉, https://www.google.com으로 되어있는 부분은 host입니다. 그 뒤에 /path가 입력되어야 Resource가 파일인지 디렉토리인지 알 수가 있는데, .com까지만 입력된 상황에서는 아직 아무것도 알 수가 없어요. path자체를 명시하지 않은 상황인거죠.
그런데 HTTP 스펙에 따르면 Request를 보낼 때 path는 생략할 수 없는 요소입니다. 저게 없으면 서버는 URL을 이해할 수 없어 400 Bad Request를 띄웠어야 합니다. 자기가 이해할 수 없는 불완전한 URL이니까요.

이대로는 무서워서 잠을 못 자겠습니다. 아무래도 이게 어떻게 된 일인지 Header를 까봐야겠어요.
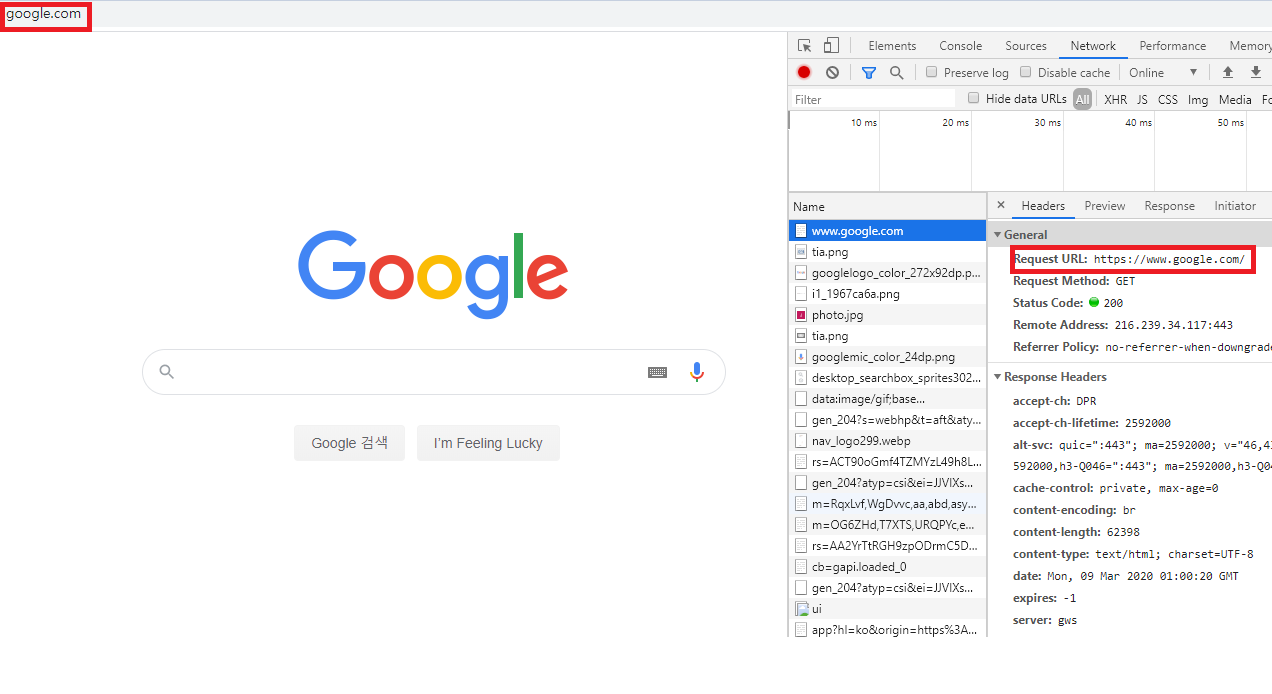
URL입력하는 부분에는 google.com으로 입력했지만 브라우저의 header에 request URL에는 /가 포함되어 있는 것을 볼 수 있습니다. 게으른 인간들을 위해 브라우저가 대신 요청을 보내주고 있었네요! 그러면 다시 주소를 살펴볼까요?
https://www.google.com // 브라우저에 의해 URL 변경
-> `https://www.google.com/` // Google.com의 루트 디렉토리의 index 파일을 색인아, 이래서 우리는 google.com에 접속할 수 있었던 거군요!
만약에 file리소스인데 trailing slash가 포함된다면?
가장 처음에 설명했듯이 Trailing Slash의 유무는 파일인지 디렉토리인지를 명시하는 역할을 합니다. 하지만 다들 귀찮기도 하고 별로 깔끔해보이지도 않으니까 생략하는 경우가 많고, 대부분의 경우 별다른 문제가 발생하지는 않아요. 하지만 그건 위에서 살펴본 것처럼 디렉토리 resource에서 빼먹는 경우만 그런거고, 이게 파일인데 trailing slash를 붙이는 경우라면 어떻게 될까요?
우리, 이 글의 처음으로 돌아가봅시다.

우리의 웹서버는 파일이 없을 때 동명의 디렉토리로 검사하는 행위는 대신 해주지만, 동명의 디렉토리가 없다고 해서 파일을 검사해주지는 않습니다. 그러니까 서버는 이것을 디렉토리로 인식하고, 404 Not Found를 띄워줄거예요.